 The next release of the Mobile Molecular DataSheet (MMDS) app will have a fairly major new feature: pipelining. First let me point out that it is not the grandiose feature that the name might suggest. Pipelining usually suggests a graphical layout tool allowing arbitrary nodes with multiple branches and huge volumes of data with sophisticated calculations at each step, and the new feature is much more constrained. But it is still useful, and intended to evolve into a midpoint compromise between power and simplicity. The system is engineered to provide linear pipelines (e.g. no branching, no alternative pathways, etc.): any number of datasheets can be jammed into the input funnel, but the outcome is always just a single resulting datasheet. The kinds of operations fit into 3 categories: filters, sorts and web operations. Filters are boolean logic clauses used to reduce the number of rows, sorts are are exactly what they sound like, and web operations are going to be implemented in a later iteration (keep reading for more about that).
The next release of the Mobile Molecular DataSheet (MMDS) app will have a fairly major new feature: pipelining. First let me point out that it is not the grandiose feature that the name might suggest. Pipelining usually suggests a graphical layout tool allowing arbitrary nodes with multiple branches and huge volumes of data with sophisticated calculations at each step, and the new feature is much more constrained. But it is still useful, and intended to evolve into a midpoint compromise between power and simplicity. The system is engineered to provide linear pipelines (e.g. no branching, no alternative pathways, etc.): any number of datasheets can be jammed into the input funnel, but the outcome is always just a single resulting datasheet. The kinds of operations fit into 3 categories: filters, sorts and web operations. Filters are boolean logic clauses used to reduce the number of rows, sorts are are exactly what they sound like, and web operations are going to be implemented in a later iteration (keep reading for more about that).
As the first screenshot shows, there is a new icon under the datasheet menu, with a representation of a joined pipe, with arrows denoting the flow. As the icon suggests, the flow is entirely linear, because this is a simplified system. Selecting the icon brings up the starting point for setting up a pipelining operation:

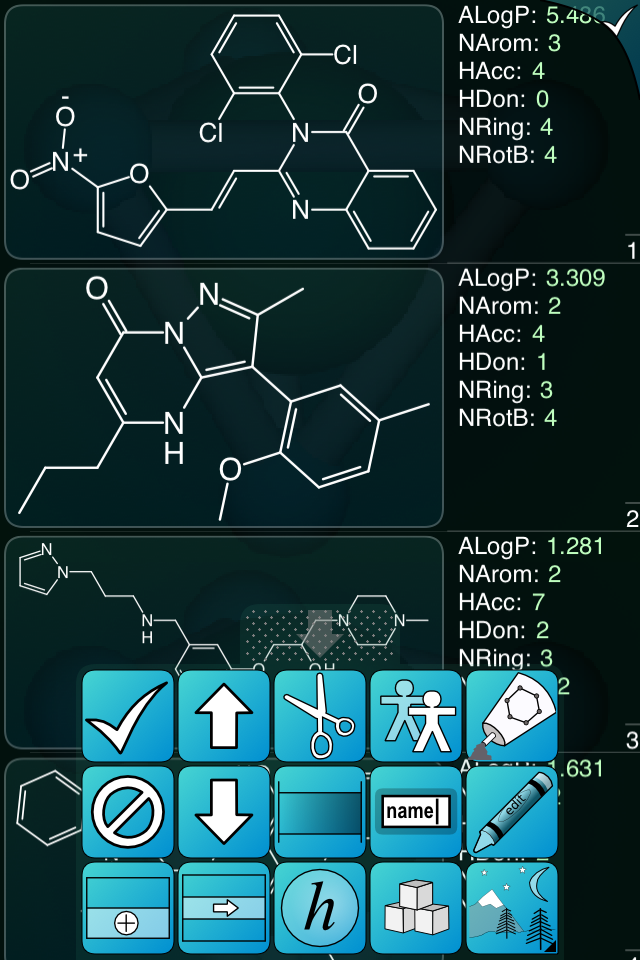
The user interface for setting up a pipeline is a vertical scrolling list of widgets. In the first section, you define the inputs, which consists of a way to select from your current list of datasheets, of which there can be more than one: they will be preconcatenated at the beginning.
After setting up the inputs, any number of steps can be added, which are currently limited to filters and sorts. Each filter is a collection of boolean clauses, which can apply comparison logic to given field values, e.g. equals, less/more than, string contains, is/not blank, between range, etc.


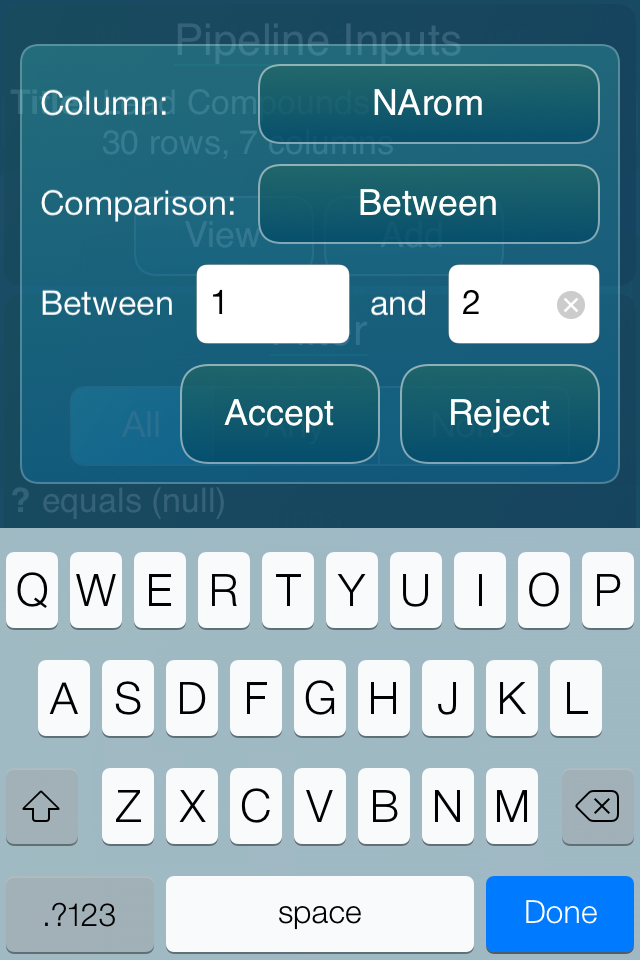
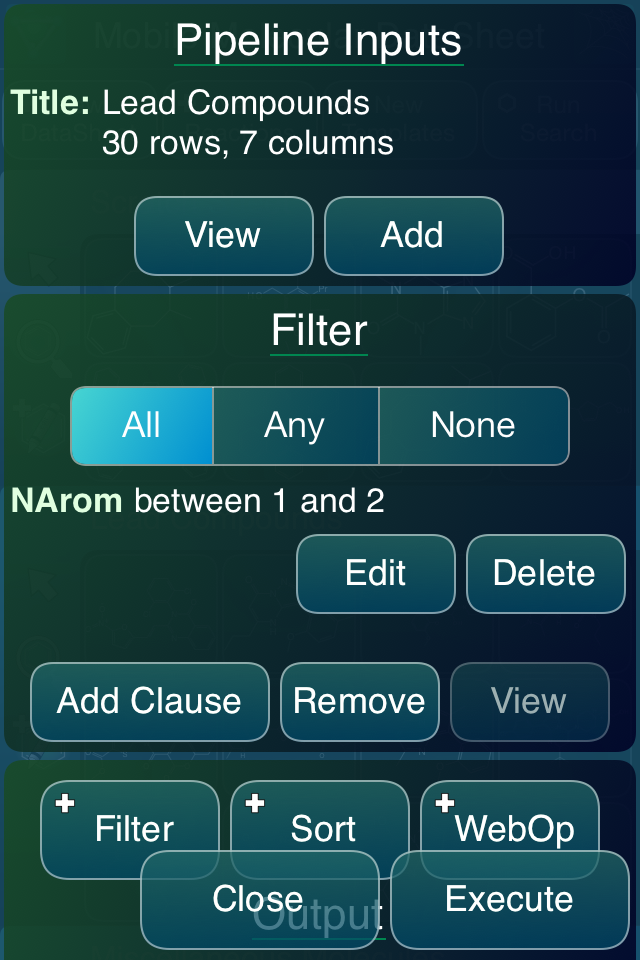


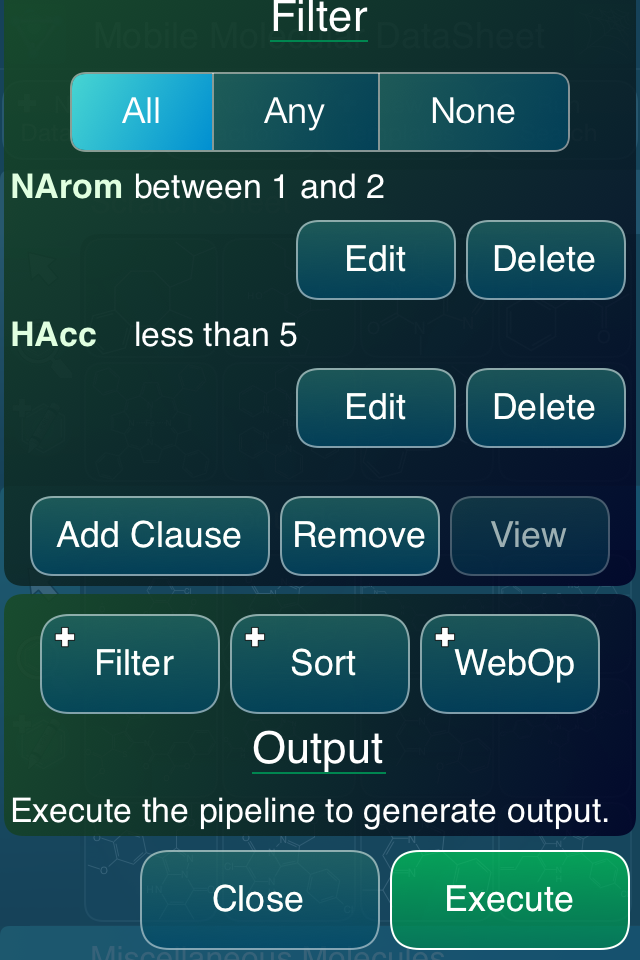

At any point, hitting the Execute button carries out any of the steps as necessary. If the final result ends up with some number of rows (i.e. was not filtered down to nothing), the button changes its name to Import:
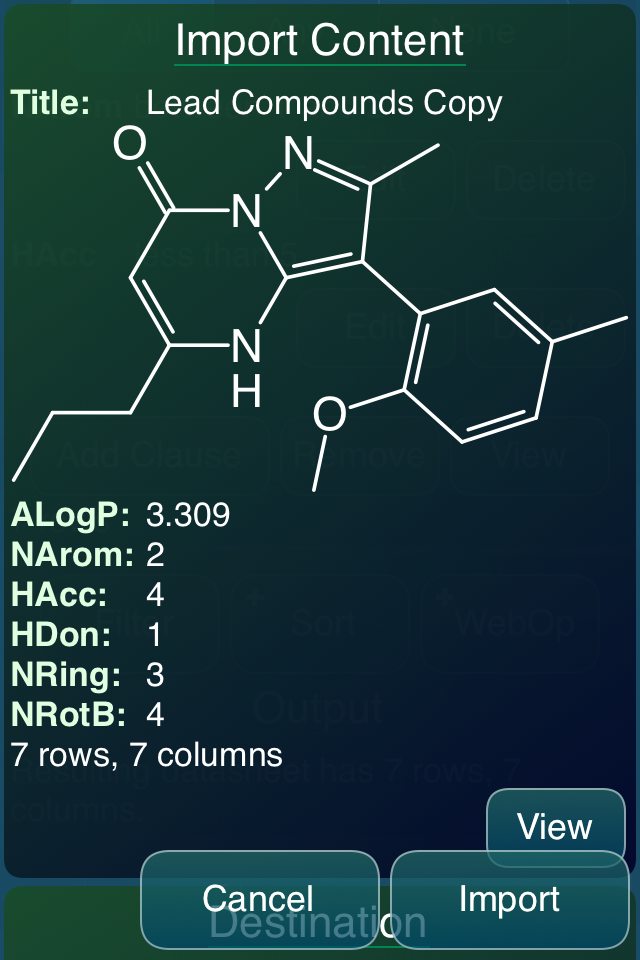
Importing the result of a pipelining operation is the same as bringing in a new datasheet from an external source, which is one of the reasons why the user interface and workflow for importing was revamped as a prerequisite. It is, however, also possible to view the results at the conclusion of each step, so the pipeline can be visually inspected: sometimes just looking at the result is enough.
In terms of workflow, this general purpose pipelining interface is a way to solve a number of data management problems. Whenever a collection of structures + data gets larger than a few screenfuls, managing it one row at a time becomes cumbersome and unwieldy. The MMDS app has the ability to manage quite a bit of data alongside structures, and can even produce some of it (e.g. property calculation) or bring it in from searches; for some time now it has been good at handing the data off to other locations by various sharing methods, and creating graphics. But simple ways of working with the data, beyond browsing it, were conspicuously absent.
With the simple pipelining features, it is possible to carry out tasks such as creating a subset with properties that are in a certain range; it is possible to find specific instances, such as by string searching (e.g. name); or to order the collection by the values of fields, to get a better idea of what is contained within. For example ordering by molecular structure currently just sorts by number of atoms, but even that trivial feature can make manual de-duplication of a few dozen compounds into an O(N) human time operation, rather than O(N2).
As useful as these quasi-trivial features are, things will get really interesting with the next major iteration, when the web operations are implemented. These will be available from a cloud-hosted website (publicly on molsync.com, but privately licensable). The list of operations will be defined as an unmodifiable collection on the server, but there is a framework for making it quite easy to script them together (using a workflow framework that runs on the server, and wraps a series of well defined steps into a single composite operation of general interest). The pipelining operations will contact the server to obtain a specification of each available operation, its parameters, description, and various meta-properties. When they are executed, the app will send the entire input through to the server, await the processing (with progress indication), and download the result. This no-state/low-state approach is quite viable given that datasheets are capped at 1000 rows of content, which is seldom more than a couple of megabytes of bandwidth.
The types of web operations will include all kinds of advanced structure-handling features, like molecular substructure searching, sorting, clustering, scaffolding, etc. Implicit property calculation filters. Probably a depiction-layout feature eventually. The technical limitations will be lifted to a large extent, because the hard work is done on a powerful server, with a robust cheminformatics framework.
While the actual flexibility of these “prefabbed” web operations are planned to be very constrained relative to some of the fully featured pipelining operations that are currently available for desktop computing, the underlying technology is designed to be eventually exposed into something that really is quite grandiose. But one step at a time.
