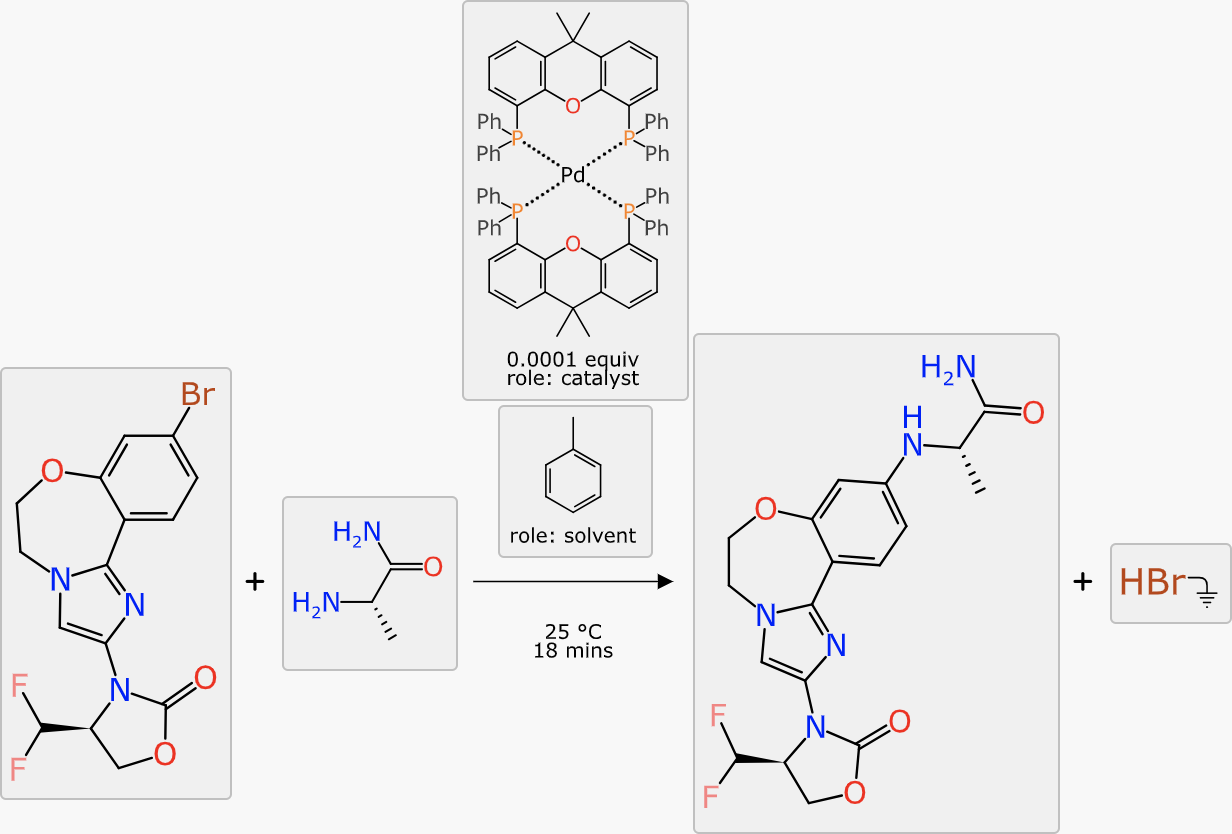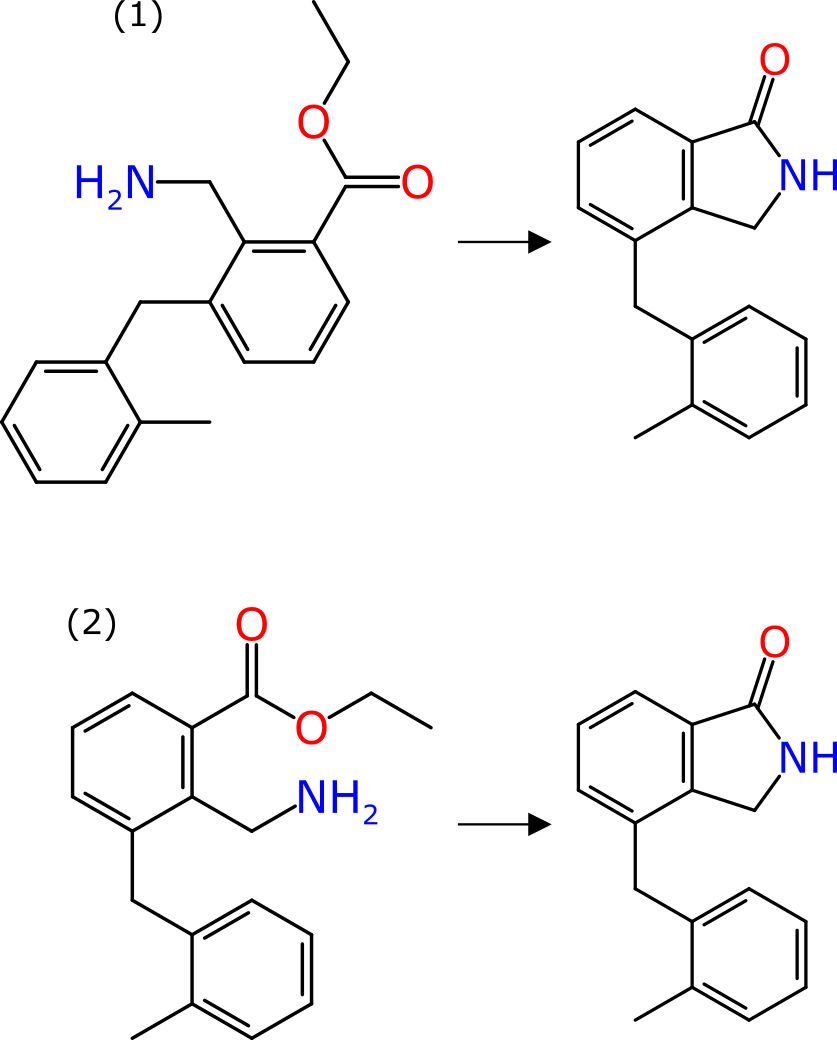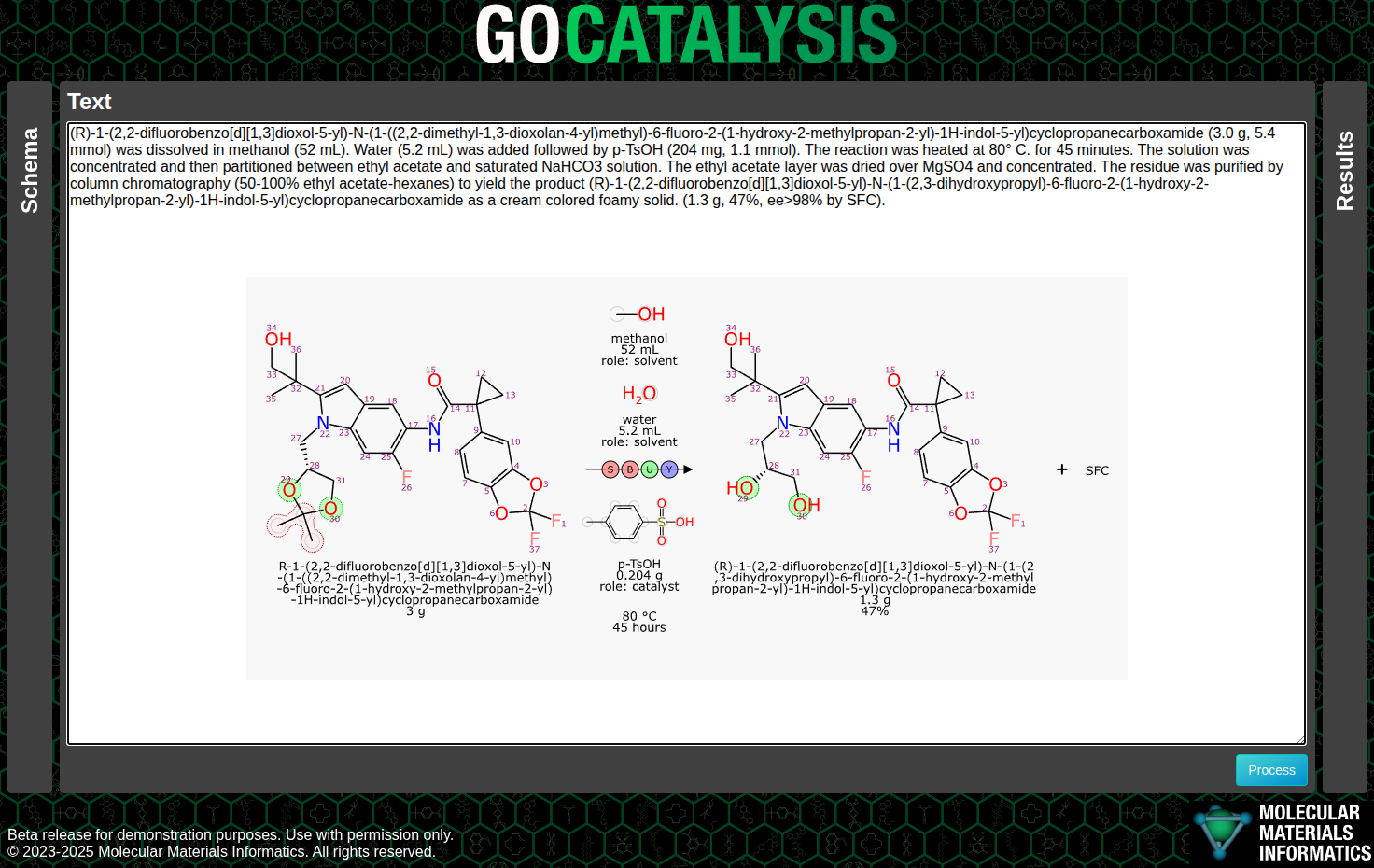
Large Language Models (LLMs or, in the parlance of our times, “AI”) have some potential value for reversing the translation of chemical reaction experiments into scientific English, into something more digitally friendly. Or put another way, there is an enormous amount of chemical reaction data that exists only as text, and if there was a less labour-intensive way to extract it, we would be much better off.
Continue reading