 As a continuation of the previous post about generating scaffolding schemes to help search for new tuberculosis drugs, the next step is to pose the question: what about known compounds that fit into the structure-activity scheme, but haven’t been tested for activity against TB? As it happens, this question can be answered by scripting in some preexisting functionality.
As a continuation of the previous post about generating scaffolding schemes to help search for new tuberculosis drugs, the next step is to pose the question: what about known compounds that fit into the structure-activity scheme, but haven’t been tested for activity against TB? As it happens, this question can be answered by scripting in some preexisting functionality.
That part involves a feature called MetaSearch, which is already available in production form via apps such as MMDS, MolPrime+ and SAR Table. The MetaSearch feature is a serverside component that provides a wrapper layer that in turn calls out to ChemSpider, PubChem and ChEBI and provides a unified API and various adaptive or value added features, most importantly in this case being scaffold template resolution.
For example, consider searching for this template:
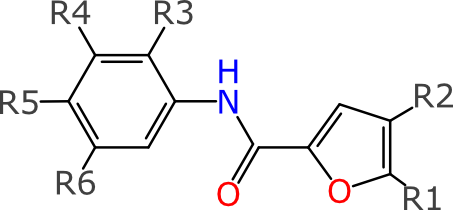
The core functionality is a substructure search, with the labels trimmed off, and this is what is sent out to the underlying database engines, which are responsible for the heavy lifting. What happens after each substructure search result comes back is as follows:
- Any result that is already present in the collection (i.e. one of the compounds with known activity or lack thereof) is omitted. Duplicate results (e.g. the same result from two different search engines) are merged together.
- The structure is subjected to a scaffold substructure search, which matches up the R-group labels, checks their validity, and generates all distinct possibilities in the case of degeneracy (e.g. if the scaffold contains symmetry, or can be matched to the structure in more than one way).
- If there is more than one distinct set of R-group fragment values, they are scored according to how well each set matches existing fragments, e.g. in this example one match might yield two possibilities, such as R4=phenyl,R6=chloro or R4=chloro,R6=phenyl; if there was already a case where R4=phenyl, that might serve as a tiebreaker to bias the selection.
- For the purposes of this project, any result that does not have at least one R-group that matches an existing fragment is deleted, since we want to augment existing grid cells, without creating new rows or columns.
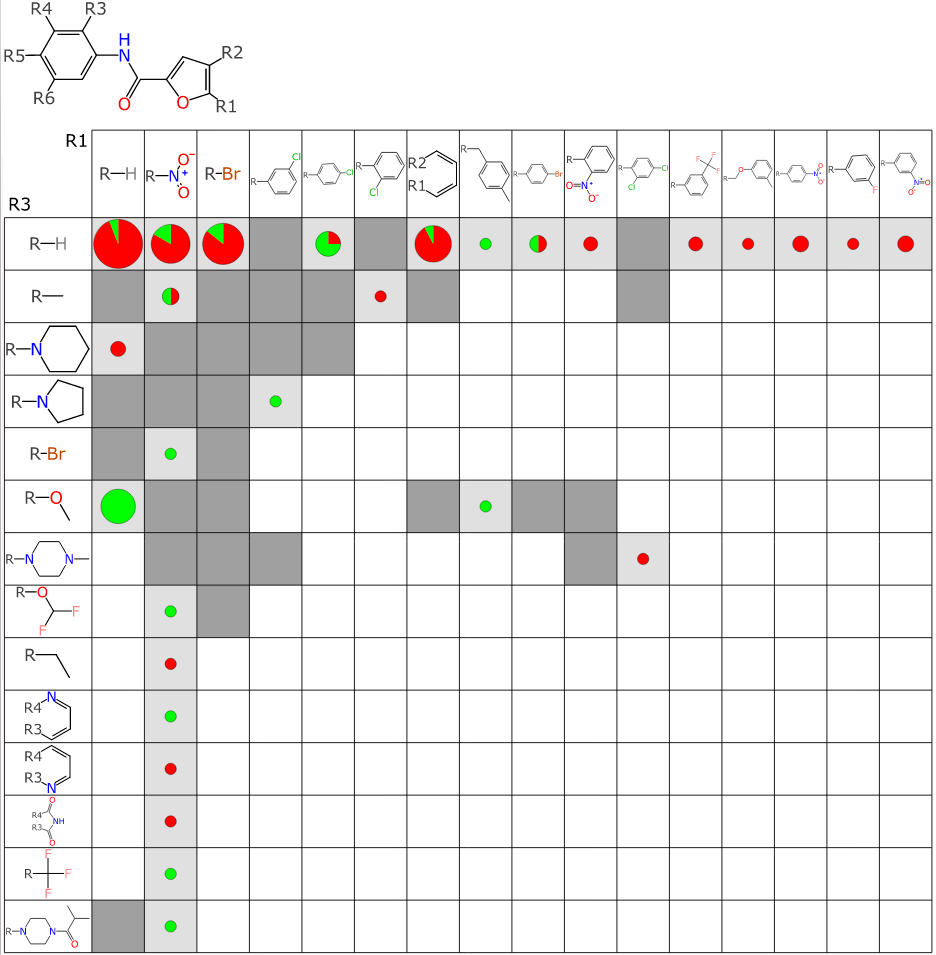
Now when the matrix plots are created, there is an additional annotation method: any grid cell that does not correspond to compounds that have active/inactive data, but does correspond to compounds that were found by searching public databases (hence activity data currently unavailable) is annotated by a darker shade of grey, and no red/green colour coding.
This means that in addition to being able to “eyeball it” to look for rows/columns that appear to code for activity, special attention can be given to such regions that have some number of available known compounds.

Note the green arrows: this row+column pair maps to the existence of a compound that has been measured as being active against TB. Both the row and column to which it belongs have a number of instances where at least one additional compound with the same scaffold and R1 & R3 fragments are known, which suggests that there is a good chance that one of these might also be active. The red arrow on the other hand hints at the opposite possibility: if you had to guess, you might say that compounds that match this row+column would likely be inactive.
The purpose of looking up compounds in public databases is a very pragmatic one: if a chemical structure has made its way into a public database, it implies that somebody has prepared it, and there is a high chance that it might be commercially available, or if not, it ought to be possible to find a literature reference to find out how it is made. For a lab on a budget and in a hurry (as many rare & neglected disease researchers are), the commercially available part is particularly interesting, and the MetaSearch feature is currently able to pull out vendor information when it is available from PubChem.
And just for the record, this line of inquiry is intended not just as a thought exercise, but some of the predictions will hopefully be executed on: there’s a small but nonzero chance that we might actually discover something interesting that gets us closer to a much needed new drug for controlling tuberculosis. And all with public data, done at very low cost.
