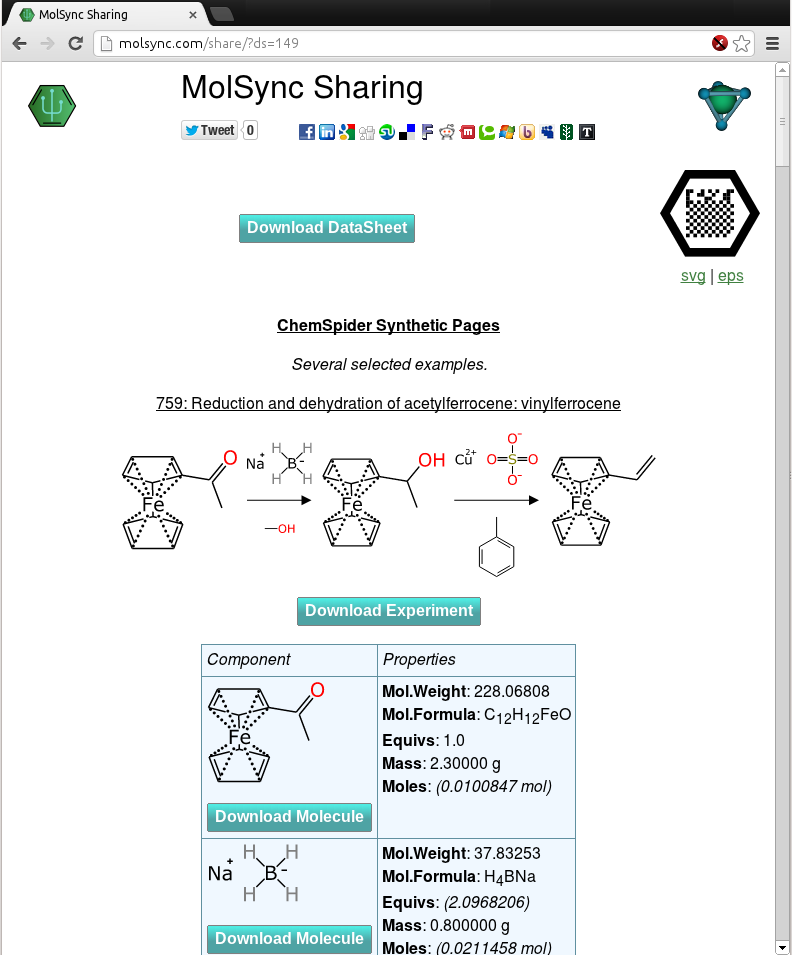
 Now that the molsync.com service has been upgraded so that it can produce human-readable pages with experiment details generated by the Green Lab Notebook app, it is time to demonstrate some of these. The snapshot to the right shows a screen grab of a collection of experiments that were manually keyed in from the ChemSpider Synthetic Pages service. Unlike the original data, though, the schemes have been carefully constructed so that each and every atom is accounted for in the chemical structure representations, and whenever possible all byproducts are accounted for, all stoichiometric reagents are correctly balanced, and quantities are entered in a standardised form.
Now that the molsync.com service has been upgraded so that it can produce human-readable pages with experiment details generated by the Green Lab Notebook app, it is time to demonstrate some of these. The snapshot to the right shows a screen grab of a collection of experiments that were manually keyed in from the ChemSpider Synthetic Pages service. Unlike the original data, though, the schemes have been carefully constructed so that each and every atom is accounted for in the chemical structure representations, and whenever possible all byproducts are accounted for, all stoichiometric reagents are correctly balanced, and quantities are entered in a standardised form.
One of the most important distinguishing features of the Green Lab Notebook, besides being a mobile app, is that it operates on a datastructure that is designed to capture a chemical reaction in a cheminformatically meaningful way. This is in contrast to traditional computerised reaction drawing approaches (e.g. ChemDraw), which are focused on helping the user create nice representations of what they would have otherwise drawn out on paper, but are frequently ambiguous (or outright meaningless) from a machine interpretation point of view. Commonly used cheminformatics formats (like MDL RXN and RDF) tend to limited in the sense that they are unable to formally capture nuances like stoichiometry and component roles, poorly designed use of abbreviations, and not to mention their inability to handle nonorganic molecules in any reasonable way.
Taking a machine interpretable reaction format and render it up in a way that is at least reasonably agreeable to chemists requires a fair bit of algorithmic sophistication, and there has been a lot of work on this, both within the app and the serverside libraries used to create data for export formats, like HTML/SVG and Microsoft Word. This is coming along quite well, and has recently been joined by the MolSync data sharing service, which produces its own stylised output for experimental content.
The best way to see it is to take a look:



The first two chemical documents are Experiment datasheets that each describe the new chemistry that was published in the first two peer reviewed papers from the beginning of my lab career (the first one from my Masters research, the second being the first publication-worthy results from my Doctoral research). This information is out there in the literature in the form of PDF files, and some ink on dead-trees, and a long lost floppy disk that contained the original computer-drawn graphics, in a format that was not usefully meaningful to cheminformatics software. Now, with a well structured dataformat that can be downloaded by anyone with the link in either its raw form or an on-demand graphical rendition thereof, in principle this research is now readily available to any suitably intelligent database that wishes to curate the content and do something with it.
The third document contains several reactions that I picked more or less at random from the ChemSpider Synthetic Pages service. This is an idea that I’m personally quite partial to, since I’ve always been an advocate of having successful chemical reactions published, regardless of whether they are exciting enough for inclusion in a conventional manuscript. The only problem is that just like every other publication, the content is a combination of quasi-informatics diagrams and human readable text, with a bit of automatic text mining thrown in. The actual definition of the reaction taking place is still intractible to a machine learning algorith, but not so for the redrawn versions from the Green Lab Notebook app, shared publicly on molsync.com.
