 The BioAssay Express project has been moving forward at a solid pace: several important new features have been added or improved for locating assays and inspecting them, with an eye toward performing some sophisticated analysis and model building. This is motivated by the fact that we have curated quite a few assays (~3,500) which is sufficient reason to start putting real effort into figuring out what we can actually do with this high quality professionally annotated data.
The BioAssay Express project has been moving forward at a solid pace: several important new features have been added or improved for locating assays and inspecting them, with an eye toward performing some sophisticated analysis and model building. This is motivated by the fact that we have curated quite a few assays (~3,500) which is sufficient reason to start putting real effort into figuring out what we can actually do with this high quality professionally annotated data.
As a brief recap for anyone who hasn’t been following the unfolding story, the general idea of the BioAssay Express project is that bioassay protocols used to evaluate small molecules are described using plain text, if you’re lucky; and in a digitised document format, if you’re even luckier. This does nothing much for machine algorithms, and for this purpose the BioAssay Ontology (BAO) was invented, to facilitate using semantic web terminology to make these experiments compatible with the world of open linked data. Realising the potential of this vocabulary has been slow, which is why we invented a schema datastructure for imposing our “grammar” as an extra layer (using our Common Assay Template initially, with others to follow). This is implemented and deployed and available to the world, starting with the annotation page, which has been designed to make picking the relevant semantic annotations as fast and painless as possible.
In order to improve and debug the annotation process, we pulled in subset of the collection of bioassay protocols stored in PubChem, and annotated a few thousand of them as well as we could, given the available information, the state of the available ontologies, and our understanding of how to use them. While we have a little bit of quality control remaining to be done on these assays (which can be conveniently viewed), it does already put us in a good position: we have a level of machine readable annotation that goes well beyond any publicly available information about assays. And so the next step was to leverage the fact that each assay from PubChem is also associated with compounds and measurements (as described earlier). By pairing the structures, activities and assay protocol details, we can start asking some fairly interesting questions.
Asking questions about data is done best by mixing easy to use queries with effective ways to visualise the outcomes, and this has been a priority lately. At the moment there are two major ways to go hunting for assays by starting with a generalised notion of what one wishes to find: Search and Browse. The Search page provides a way to search for assays that are similar to the given constraints, and can be used in a way that is analogous to doing a similarity search for a molecular structure. The Browse page on the other hand is more interactive, and allows the user to define a series of layers, each of which narrows down the database, showing the results interactively.
In the example below, a single layer of criteria is defined for the target assignment category, which includes all assays that are annotated with any of the terms that are nested under the GPCR hierarchy:

…

As terms are toggled on or off, the list of qualifying assays is updated underneath:

This feature has been available for awhile, but a couple of modifications have been made recently. One of them is an additional column that shows how many compounds are associated with each assay, which is a rather important detail, since the source content tends to include a lot of high throughput primary assays, and a lot of much lower throughput secondary assays of various kinds. These are frequently applicable to quite different kinds of studies, and with this interface they can usually filtered out using the appropriate annotation field (assay campaign stage), but they can also be selected explicitly by clicking on the checkbox to the left.
Underneath the list of qualifying assays is the visualisation feature that is most particularly new – the property grid:
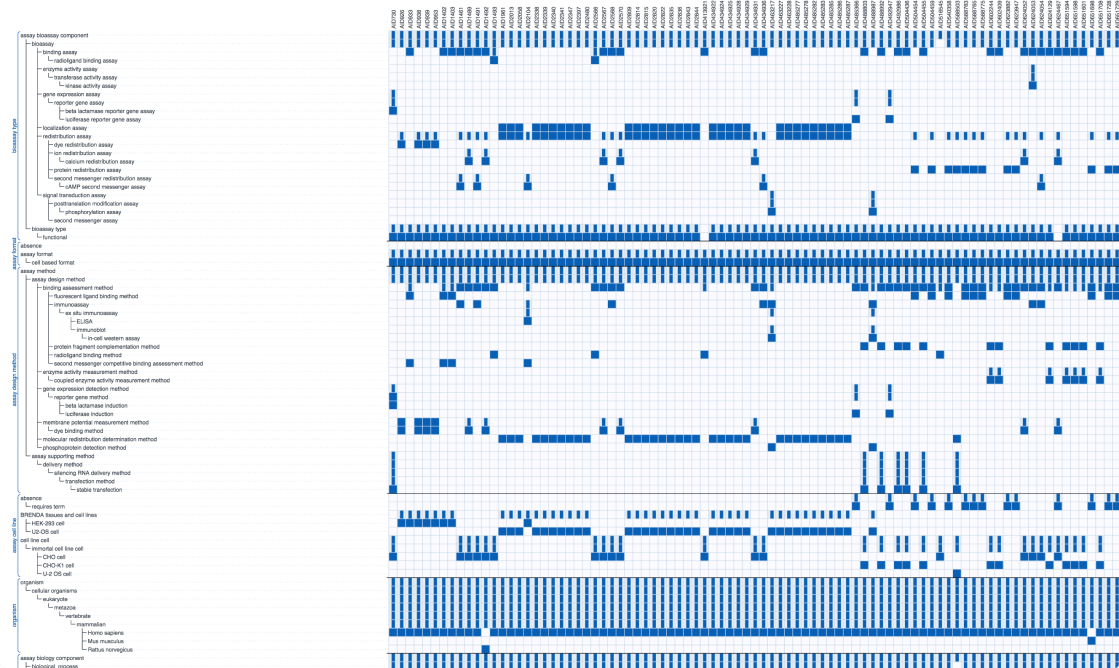
You may need to click on the image and zoom in a little, since there is a lot of information crammed into the grid.
The purpose of this display is to show what is actually being selected in the result set. The list of assays with the first line of their text description is all well and good, but for many purposes, it is essential to get an overview of the actual terms that are stored within each of the results. And so this grid plots the assay results as columns, and as rows it uses the hierarchy of all the terms (limited to those that appear in at least one of the results, otherwise it would be way too huge). Each cell has a full sized blue square if the term was used explicitly, or a narrow rectangle if that term is an ancestor of one that was.
If one thinks of each term as a discrete assertion, then this view essentially displays the assay fingerprints for each of the results. The idea of thinking of the terms as fingerprints is very much analogous to structure-based fingerprints which is a core concept of cheminformatics that enables a lot of functionality (searching, similarity ranking, clustering, Bayesian models, to name but a few). We have already demonstrated one fingerprint-like use for the annotations (the Searching feature), and are following up by looking into ways to build models using this content as input. For example, creating a Bayesian model by mixing assay & structure fingerprints to predict activity, as well as looking for patterns that are predictive/anti-predictive; or unleashing the latest trendy deep learning techniques to try to maximise the accuracy of such models.
To facilitate some more preliminary explorations, there is an additional toggle whose purpose is not completely self-evident, Query:

Activating this shows a line notation query for the terms that were used to select the list of assays (either as a query proper, or by a list of ID numbers to achieve the same effect, which is updated to reflect which of the assays have been checked). This is currently being combined with an API (undocumented for the moment) that allows assays + compounds to be remotely dragged out of the database, in a form that can be fed into exotic modelling tools.
The actual compounds that are associated with the selected assays can also be viewed by pressing the Show Compounds button:
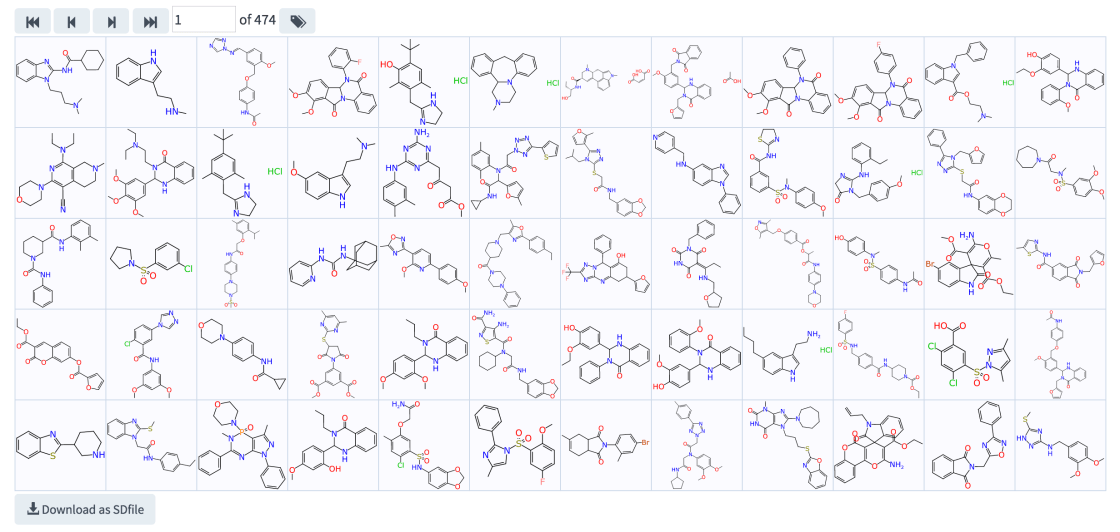
This workflow has been described in a recent post: it is an effective way of finding and joining SAR data for assays of interest, making it easy to download the whole thing as an SDfile for followup use.
The bottom line is that the tools for browsing, selecting and acquiring data from the assays that we have curated + the molecules and activity measurements that were deposited are taking shape and becoming very powerful. We are actively using these for our own explorations, experiments and collaborations, but they are also available publicly who is interested in making use of the tools and data.
