 At CDD we’ve recently begun a new project to define a common format for mixtures of chemicals, along with an open source editor, and impending tools for generating data from text content. The work-in-progress editor is now openly available on GitHub.
At CDD we’ve recently begun a new project to define a common format for mixtures of chemicals, along with an open source editor, and impending tools for generating data from text content. The work-in-progress editor is now openly available on GitHub.
The story behind this one is an unusual combination of high value and relatively low difficulty. If someone were to ask you for a recommendation for a good file format that can be used to describe mixtures of chemicals, it’s quite likely that you might think that there must be something out there, but the specific example doesn’t quite spring to mind. It turns out there actually isn’t anything that fits the description, and this is a major shortcoming, because in the world of physical reality, almost all chemical substances are mixtures.
A handful of the many bottles found in a typical lab will be effectively 100% composed of just one specific compound, with negligible impurities (e.g. high purity dry solvents spring to mind), but almost every nominally single-structure material that comes in a bottle has a purity caveat like “98%”, or is an adduct of some kind (e.g. water of crystallisation), or is dissolved in a solvent, or is some other kind of multi-component material. Someones all the ingredients are easily described molecules, othertimes they are amorphous polymers (or things like diatomaceous earth, which is not what it sounds like).
The standard way of dealing with this is to simply write out the description using compressed mnemonics, which are very chemist friendly – but not so much to machines – such as:
osmium tetroxide 2.5 wt. % in tert-butanol n-butyllithium 2.5M in hexanes
This causes all kinds of problems, one example being inventory systems: it is quite common to capture the active ingredient of a substance in some formal way (e.g. Molfile or InChI) which leaving the remaining context as machine-intractable text. This partial description does help for narrowing down stocks of interest, but the rest is important too – especially when it comes to hazards & safety. Among many examples that spring to mind, one is the difference between white phosphorus stored in an inert gas, and white phosphorus stored under water: one of them will ignite immediately on opening, while the other will seem innocently benign until the water is gone, and only then will it burst into flame. When you’re clearing out leftover samples from a recently graduated chemist, these are things that you need to know.
This absence of any standard way to describe mixtures in a machine readable way with any degree of standardisation began to be addressed by an IUPAC working group, which proposed a new use case for the well known InChI identifier: a mixtures InChI, or MInChI for short. The idea of a MInChI string is that it is made up of several constituent molecular structures, each of them defined by its own InChI identifier, combined with quantity information where available. This composite encoding leverages the canonical characteristics of the underlying InChI identifiers, though there are still multiple ways to describe a comparable substance (e.g. using a range of concentrations where the exact amount is known, or molar vs. mass concentrations). Using MInChI strings to represent mixtures in databases can greatly simplify the cheminformatics part, even if it’s not quite as simple as doing an exact string match (as is the case when using single InChI identifiers for single molecules).
The one big problem with the MInChI project that IUPAC is proposing is data. The scientific community must have literally billions of records where a mixture is described in some digital form, but almost all of these are text. What is needed is some kind of rich description that precedes the MInChI, much like the way a Molfile typically precedes a regular InChI.
Enter the Mixfile.
The format hasn’t been locked down yet, but it is very simple: it’s JSON-based, in order to make it easy to read & write with any software platform, and have high human readability. It’s hierarchical, making it possible to describe mixtures-of-mixtures, which happens frequently. Each component is expected to provide a structure and quantity whenever these are known, with name being also highly encouraged. Other information like canonical identifiers, database links, cross references, etc., can easily be encapsulated – the Mixfile is intended to be an inclusive container of information – but they do not necessarily impart much-if-any special meaning to the software that interprets them.
So far, we have a raw specification of the Mixfile, and a preliminary editor for this data format, which is written in TypeScript (cross compiles to JavaScript, so it can ultimately run on any platform):
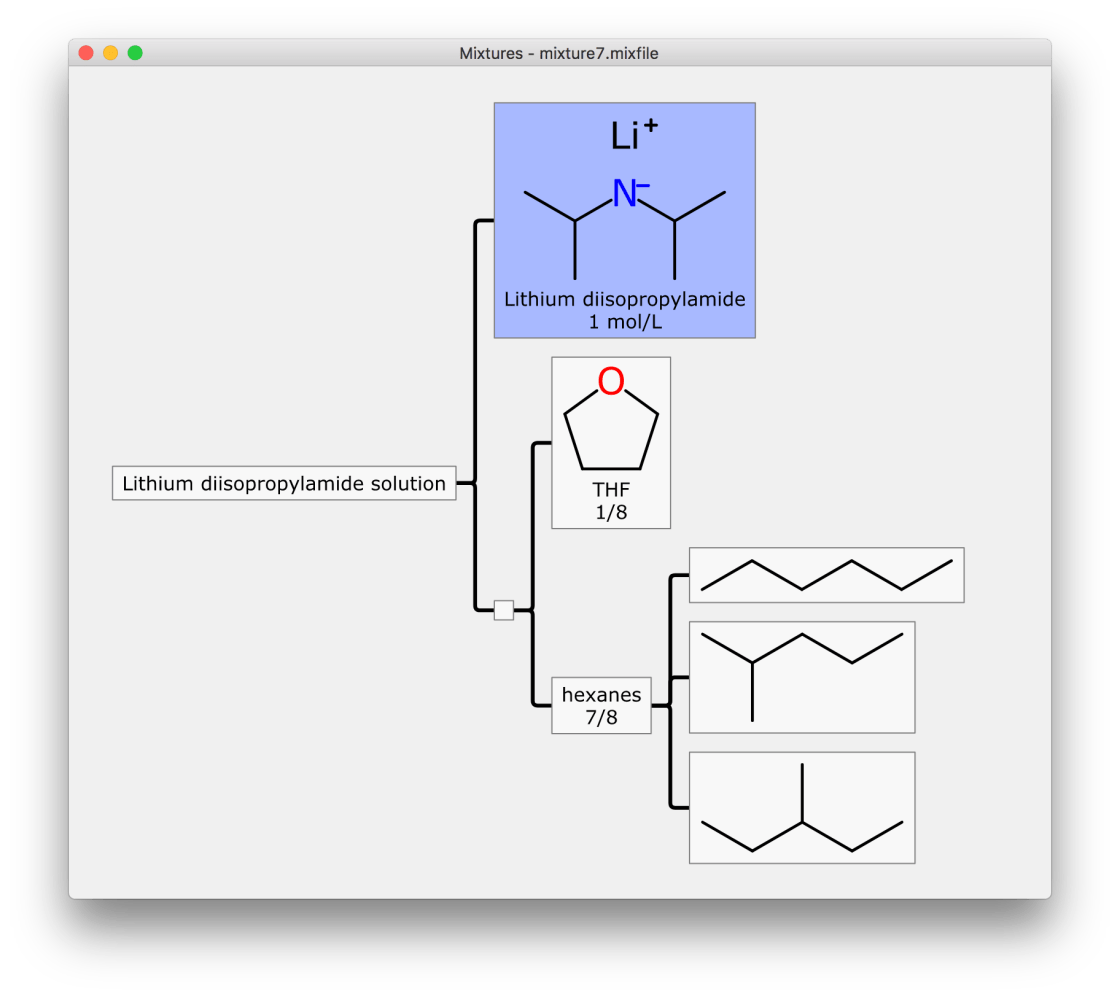
The above example is a definition of LDA within a solvent mixture of THF and hexanes, in a ratio of 1 to 7. Note the branching of the components: this is a feature of the file format, which is rendered by the editor. The root node can be used as an overall description of the mixture, while the first branch commonly splits out between the active ingredient (LDA in this case), and the rest of the content. The solvent mixture is represented by a single node, and underneath that is the two components: THF is a single molecule, while hexanes is a mixture of several isomers.
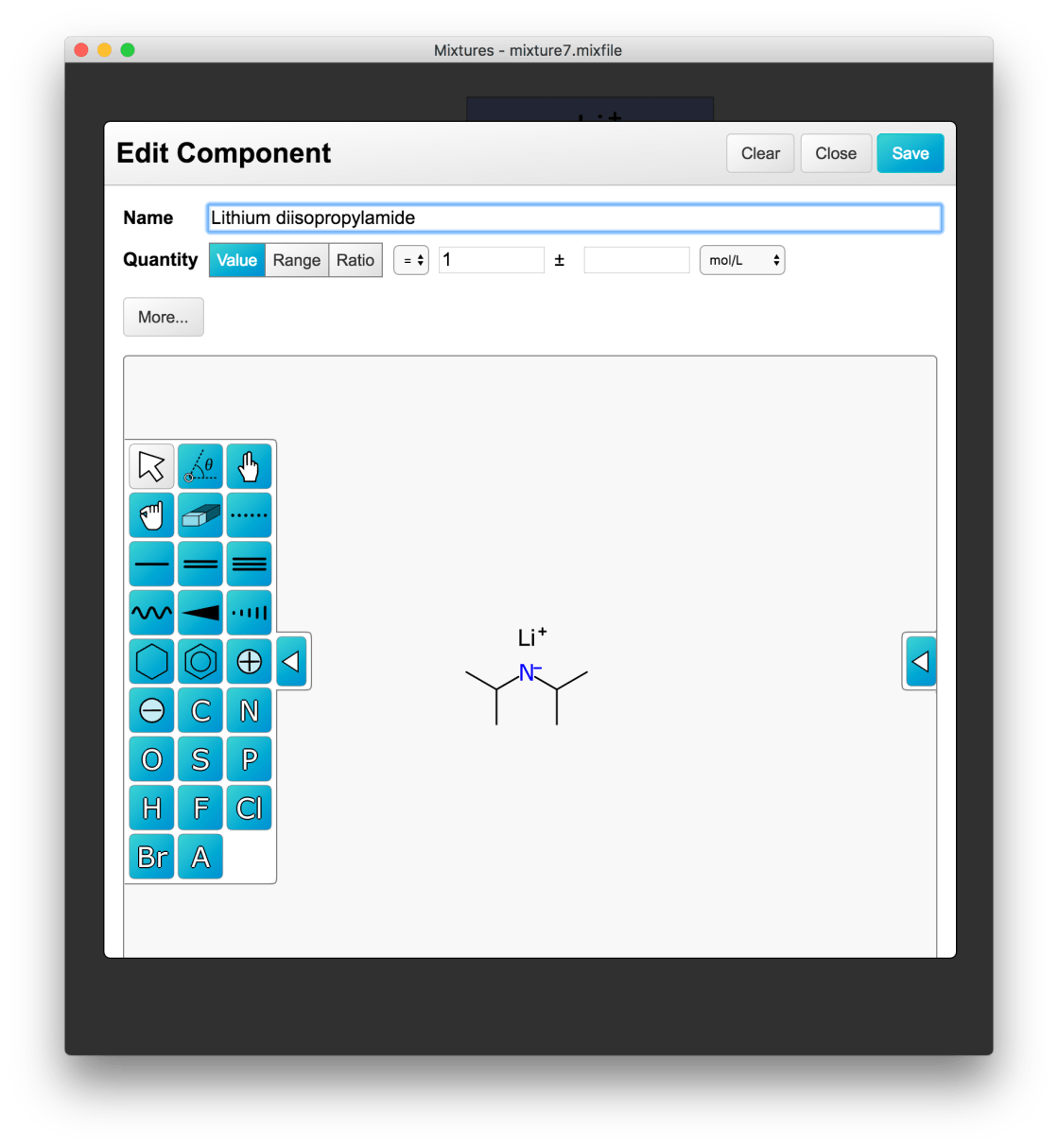
Within the editor, it is possible to define the specific components in detail, as shown below – including the structure, using the WebMolKit sketcher:
The definition of the Mixfile format has been worked on in conjunction with the IUPAC team that is advancing the new Mixtures InChI standard. The role of the format is to store a lot more information than we would want to put into an InChI derivative like MInChI, but there are certain things that are important to sync up: the way that we handle hierarchies of mixtures-within-mixtures, and the available unit options (percentages, ratios, concentrations, ranges thereof, missing information, etc.)
At the time of writing, the mixture format and editor are barely functional, but moving along quickly, so you are welcome to take a look at the GitHub page. We are able to make this open source with the help of an NIH grant recently awarded to Collaborative Drug Discovery, and of course working with IUPAC is what got the whole thing started.
A portion of this project also involves building tools for pulling out mixture information from the text strings that people currently use to describe these mixtures. This is a text extraction/natural language problem, so it will never be perfect, but there is substantial value in being able to automatically parse hundreds of thousands of mixture entries and turn them into well defined cheminformatics data objects, with a fairly high recall rate. We intend to release a big chunk of our training data to the public, i.e. there will be a lot of Mixfiles that you can use for any purpose that you wish (including turning them into MInChI strings)… though the tool itself will be a commercial product.

I am a lead developer on the Open Source Chem4Word project (https://www.chem4word.co.uk Source @ https://github.com/Chem4Word/Version3-1). We have spoken to you in the past regarding other matters.
Have you considered using CML (http://www.xml-cml.org/convention/molecular) as the storage mechanism. CML already handles nested molecules.
Our next generation of Chem4Word has a WPF structure editor which can read nested molecules from cml files.
I think the changes to render a drawing such as shown above would not be too difficult to achieve.
The diagram above is simply visualising the heirechcy of structures, with some groupings having labels.
/Mike Williams (Chem4Word)
CML never caught on, for a long list of reasons (which I won’t go into)… so it doesn’t really bring anything to the table. That being said, it would be perfectly viable to write a transformer to go from CML{subset} to MInChI, assuming that some minimum variety of fields were available. Whether or not it’s worth doing depends really on whether anyone has any interest in using it.
Note: the MInChI/IUPAC page is at https://iupac.org/projects/project-details/?project_nr=2015-025-4-800